

You’re supervising in clinic. A senior resident finishes evaluating a patient with chest pain. Before presenting to you, they quietly pull out their phone, type the case into ChatGPT, and ask for a differential. Seconds later, they walk over with a confident, well-organized list.
You have three choices in that moment.
→ Shut it down (“don’t use AI for clinical reasoning”)
→ Let it slide (“not worth the conversation right now”)
→ Pause and turn it into a teaching moment
The instinct for a lot of us is option one. Eighteen months of research has told us AI use erodes thinking and weakens clinical reasoning. The message had been loud and consistent.
But new evidence suggests that message was incomplete.
Let’s unpack what changed, what it means for medical education, and how we can effective supervise the moment when AI shows up in clinic.
1. Cognitive Deskilling
Before we talk about what’s new, it’s worth grounding ourselves in how strong the existing concern actually is.
A 2025 survey of 666 participants found a significant negative correlation between frequent AI tool usage and critical thinking, with cognitive offloading as the mediating mechanism. Younger users were hit hardest.
Then came the brain scans. An MIT team used EEG to measure neural activity while 54 participants wrote essays with ChatGPT, Google, or no tools. The ChatGPT group showed the weakest neural engagement. When AI was taken away, they couldn’t recall their own earlier work. The researchers called it cognitive debt (Kosmyna et al., 2025).

For medical educators, the concerns are sharper. In the NEJM review on clinical supervision of AI, Abdulnour and colleagues note that more than a third of advanced medical students failed to spot erroneous AI answers in clinical vignettes. A JAMA study found that when clinicians were shown AI-generated diagnostic predictions with systematic biases (overestimating pneumonia in older patients, heart failure in high-BMI patients), they adopted the errors. Even AI-generated explanations failed to fix this.
The NEJM review names the 3 failure modes cleanly:
→ 🔻 Deskilling: Loss of skills you once had
→ 🔻 Never-skilling: Failure to develop the skills in the first place
→ 🔻 Mis-skilling: Reinforcement of wrong behavior due to AI errors or bias
So the story seemed settled: AI erodes clinical reasoning. Keep learners away from it.
But the picture was already getting more complicated.
2. The Cognitive Offloading Paradox
The field was gradually moving past the simple “AI erodes thinking” story.
Favero and colleagues (2025) made a specific argument: cognitive offloading only undermines learning when the freed mental effort isn’t redirected into something meaningful. Free up capacity and let it evaporate, and yes, you lose. Free it up and reinvest it elsewhere, and the picture changes.
Then in March 2026, Lodge and Loble went further. Their framing was blunt: offloading isn’t inherently harmful to learners. Whether it helps or hurts depends entirely on what happens with the freed cognitive capacity.
The conversation was moving from “is AI bad for learning?” to a harder question: when is it bad, and when might it actually help? The empirical evidence to answer that question at scale, across cultures, with a clear mechanism, didn’t exist yet.
That’s what made the Wang and Zhang study, published the same month in the International Journal of Educational Technology in Higher Education, important.
They asked a different question. Not “does offloading hurt?” but “what happens when students treat AI as a genuine intellectual partner rather than a shortcut machine?”
The study tracked 912 students across China, Europe, and the US using a three-wave time-lagged survey. Partnership orientation was measured first. Cognitive strategies two weeks later. Learning outcomes two weeks after that.
The findings:
When students scored high on partnership orientation toward AI, two cognitive responses fired at once.
→ They became more critical of AI outputs (cognitive vigilance, β=0.335, p<0.001)
→ They delegated more strategically to AI (cognitive offloading, β=0.351, p<0.001)
Both independently predicted deeper transformative learning (vigilance β=0.437, offloading β=0.333, both p<0.001). Students who delegated the most didn’t learn less. They questioned assumptions more deeply, shifted perspectives more fundamentally, re-evaluated how they thought. The pattern held across all three regions.
The paradox isn’t just that offloading helped. It’s that the same partnership orientation that made students delegate more also made them more critical. Both behaviors pulled in the same direction toward deeper learning.
Importantly, the relationship between offloading and learning wasn’t linear. A post-hoc analysis revealed a U-shaped curve (β-quadratic=0.102, p<0.001), with three clear zones.
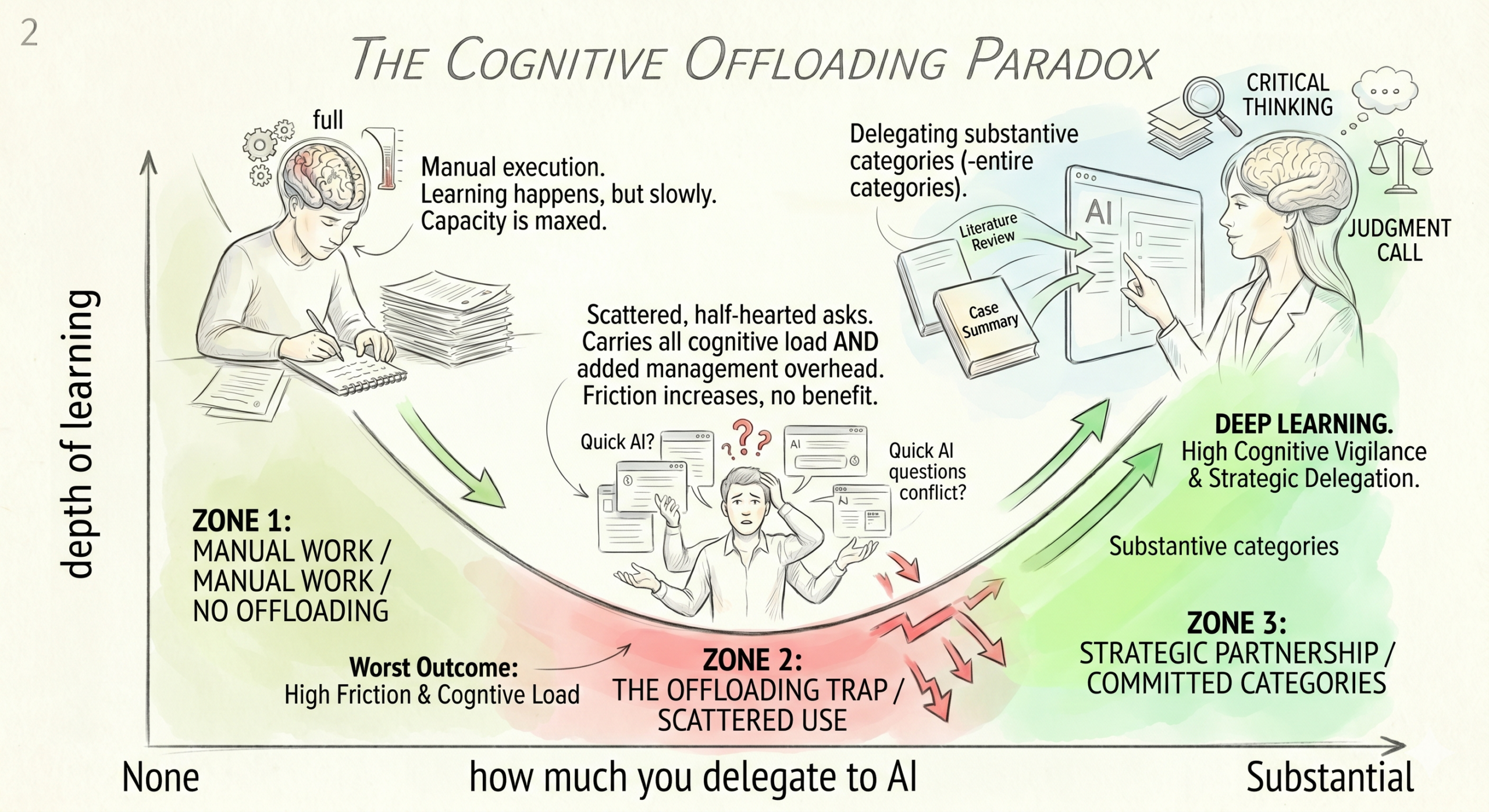
🟢 Zone 1: No offloading. You do everything manually. Learning happens but slowly. Your cognitive capacity is maxed out on execution. Nothing left over for higher-order reflection.
🔴 Zone 2: Scattered, half-hearted offloading. A quick question here, a sentence cleanup there, a random lookup. This is where most residents sit today. And it’s the worst zone. You still carry nearly all the cognitive load AND you’ve added the overhead of managing the AI (what to ask, how to evaluate it, when to switch back to your own thinking). More friction, no real benefit.
🟢 Zone 3: Committed, strategic offloading. You delegate entire categories of substantive work to AI. The savings are large enough to genuinely free cognitive capacity. That freed capacity goes into work AI can’t do: questioning frameworks, constructing original arguments, making judgment calls.
Zone 3 is where the real learning happens. Zone 2 is worse than Zone 1.
That’s the paradox. The problem with most current resident AI use isn’t that they’re using AI too much. It’s that they’re using it too scattered to get a real benefit.
3. The Google Maps Question
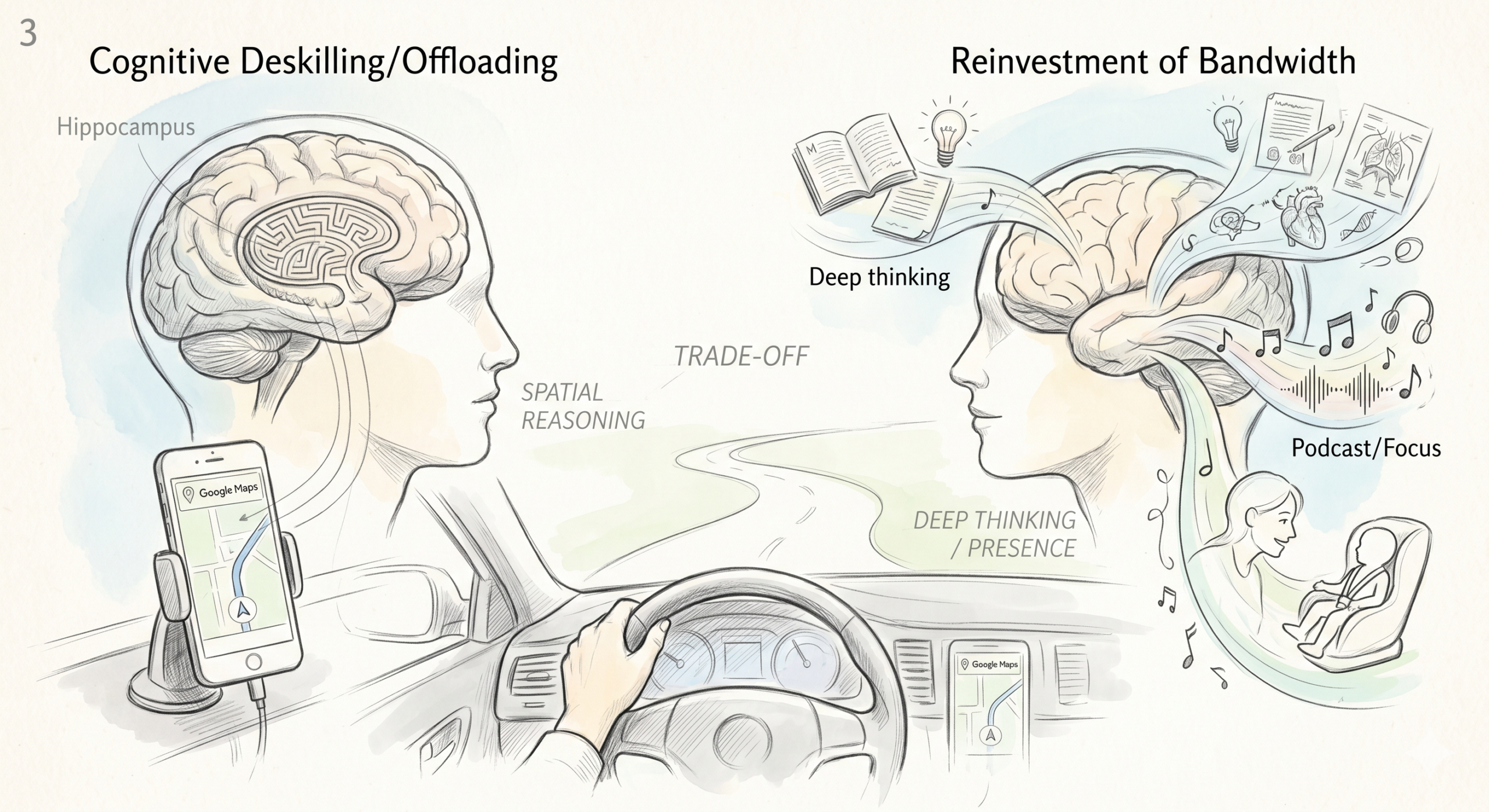
I use Google Maps for almost everything. Beyond the route to my nearest grocery store, I probably couldn’t drive anywhere without it. My hippocampus is probably a little smaller for it (the London taxi driver studies suggest spatial navigation lights up that region, and I’m not lighting it up much).
Is that deskilling? Probably yes.
Do I care? No. I made a trade. I offloaded spatial navigation to free up bandwidth for things I care about more, like podcasts, thinking through a manuscript in my head, or just being present with little one in the back seat.
And yes there are those few instances when I trusted my instinct and decided to go against Google Maps, which turned out to be my biggest mistake and being stuck in traffic for an hour.
The real question with AI in medicine isn’t “will this cause deskilling?” That’s the wrong frame. Some deskilling happens every time a new tool arrives. Physicians stopped memorizing drug dosages when UpToDate showed up. Residents stopped doing long division when calculators arrived. We’ve been trading specific cognitive skills for higher-leverage ones for decades.
The right questions:
→ Which skills are we willing to trade?
→ Which skills are non-negotiable for safe patient care?
→ What do we reinvest the freed-up cognitive capacity into?
For Google Maps, I traded navigation for mental bandwidth. Fine trade.
For medicine, the non-negotiable skills are narrower than you think but sharper than AI boosters admit. A fellow who offloads first-draft literature synthesis to AI can still be an excellent clinical researcher, if they verify rigorously and reinvest the freed time into deep reading of the key three or four papers. A resident who offloads differential diagnosis generation to AI can still be a sharp diagnostician, if they treat the output as hypothesis, not answer, and reinvest the freed minutes into patient interview depth and pattern recognition.
The trade-off isn’t binary. It’s a design decision.
The danger is making it by accident.
4. What This Means for You as a Resident or Fellow
Offload substantially or not at all
The worst thing you can do is use AI scattershot. One quick ChatGPT question per shift, a random sentence cleanup on a note, a half-hearted “summarize this paper” prompt. That’s Zone 2. Overhead without benefit.
Either commit to a workflow where AI owns entire categories of substantive work (first-pass literature review for a case report, drafting a structured case summary, cleaning up a discussion section draft, organizing your study plan), or leave it alone for that shift. The middle ground is the worst ground.
Do the thinking first. Then check with AI.
Producing your own answer first, even a wrong one, builds stronger retention than reviewing a correct one from AI. This is decades of retrieval-practice evidence.
The Zone 3 workflow for a resident:
→ Generate your own differential. Write it down.
→ Ask AI for its differential with the same data.
→ Compare. Reconcile gaps. Ask why your lists differ.
→ Verify the final list against a trusted source (UpToDate, guidelines, or your attending).
The Zone 2 (bad) workflow:
→ Ask AI first.
→ Tweak the output.
→ Present it.
You’ve done neither retrieval nor critique.
Use AI to find errors, not fix them
Ask AI “critique my differential” not “write my differential.” Ask “which of these pathophysiology connections is weak?” not “explain pathophysiology.” When AI flags the issue and you fix it, you build the skill. When AI fixes it for you, you’ve been robbed of the learning opportunity.
The productive struggle of correcting your own mistakes is what builds competence. Don’t outsource that.
Verify before you trust
Every AI output in a clinical context is a hypothesis, not a conclusion. Abdulnour and colleagues call this the verify and trust paradigm. For drug doses, dates, guideline recommendations, and citations especially, always check against a trusted source. Citation hallucination in medical AI output remains a real and documented risk.
Know when to be a centaur vs. a cyborg
The NEJM review borrows these terms from Dell’Acqua et al.’s Harvard study:
→ Centaur mode (clear division of work): For high-stakes or complex clinical reasoning. You handle the judgment; AI handles specific subtasks like literature retrieval or first-draft summarization. You evaluate everything AI produces. Example: AI drafts a broad differential for abdominal pain. You prioritize and eliminate based on the history, labs, and exam. Ask the “WHY”.
→ Cyborg mode (tightly integrated): For low-stakes, creative, or well-defined tasks. You and AI iterate together. Example: drafting a patient education handout, organizing your study plan, brainstorming research questions, structuring a grant aims page.
The skill is knowing which mode fits the task. High stakes plus high uncertainty means centaur. Low stakes plus well-defined means cyborg. Drift the wrong direction and you’re in deskilling or mis-skilling territory.
The Medical Learner Cheat Sheet
| Dimension | Instead of this… | Do this |
|---|---|---|
| AI framing | “Let me just ask Openevidence for the answer.” Passive, tool-like use. | “Here’s my thinking. Now stress-test it.” AI as sparring partner. |
| Task scope | Scattered small asks across the shift. Zone 2. Worst of both worlds. | Delegate whole categories: first-pass lit review, case summary outline, practice questions. Zone 3. |
| Problem-solving order | Ask AI first. Edit the output. | Generate your own differential first. Then compare with AI. Reconcile gaps. |
| Verification habit | Scan the output. Trust it looks reasonable. | Check one high-stakes claim (drug dose, guideline, citation) against UpToDate or primary source before acting. |
| Using AI feedback | Ask AI to fix your draft. | Ask AI to critique your draft. You do the fix. |
| Citation use | Copy-paste AI-generated references into your paper. | Manually verify every citation exists and says what AI claims it says. |
| Mode selection | Default to cyborg mode for everything. | Centaur mode for high-stakes clinical reasoning. Cyborg mode for low-stakes drafting and brainstorming. |
| Self-assessment | Only evaluate yourself on cases where AI is in your pocket. | Practice regular unassisted cold differentials and oral presentations. |
5. What This Means for You as a Supervisor
If you’re supervising residents or fellows who use AI (you are, whether you see it or not), here’s the playbook.
Don’t ban it. Surface it.
Banning AI drives it underground. Your learners are already using it. Your job is to make the interaction visible and teachable.
Use DEFT-AI to structure the teaching moment
NEJM review proposes this five-step framework:
→ D – Diagnosis, Discussion, Discourse: Ask exactly how they used AI. Which tool? What prompt? Did they verify? Example: “You reached for ChatGPT for this case. Walk me through what you typed and what came back.”
→ E – Evidence: Probe both the clinical reasoning and the choice to use AI. Example: “AI suggested temporal arteritis. What data in the history and exam supports or refutes that? And why did you think this was a task AI could help with?”
→ F – Feedback: Have them self-reflect. “Where was your AI use productive? Where was it risky?”
→ T – Teaching: Teach both the clinical content AND the effective AI use. Prompting strategy, verification habits, recognizing sycophantic output.
→ AI Engagement Recommendation: End with a specific recommendation for how they should use AI on similar tasks next time. “For syncope workup, use AI to stress-test your differential after you’ve written it, not to generate it.”
Design explicitly for Zone 3
If you tell learners “don’t use AI,” they’ll either ignore you or use it scattered-style. Both are bad outcomes.
Instead, name specific tasks AI should handle and tasks that are non-negotiable human work. Make the boundaries explicit.
Tasks AI can own (with verification):
→ First-pass literature retrieval and summarization for a case (this is likely coming soon to our EHRs)
→ Structuring a case presentation outline
→ Drafting administrative notes, patient handouts, or discharge summaries for editing
→ Generating practice questions for self-assessment
Tasks that stay human:
→ Final diagnostic assessment
→ Breaking bad news and high-stakes communication
→ Judgment calls on treatment change/escalation
→ Interpreting the patient’s own story and non-verbal cues
Assess without the scaffolding
A fellow who performs well with AI but can’t reason independently through a case at the same difficulty level has built dependency, not competence. Build in unassisted assessments regularly. Morning report. Oral case presentations with no phone in hand. A 5-minute cold differential on a new consult.
If independent performance holds, you built competence. If it drops, you built a human-AI system that only works when the AI is there.
Model the shift yourself
Your learners watch how you use AI. If you never touch AI, you signal that ignoring it is acceptable. If you use AI carelessly, you signal that carelessness is acceptable.
Show them the Zone 3 workflow in real time. “Here’s my initial differential. Let’s see if ChatGPT comes up with any additional ones. Here’s what it added. Here’s what I’m rejecting and why. Here’s my final plan.”
That’s the most powerful teaching you can do on this topic.
The Supervisor Cheat Sheet
| Dimension | Instead of this… | Do this |
|---|---|---|
| Supervision stance | “Don’t use AI in clinic.” Ban drives it underground. | Surface the AI use. Make it visible and teachable in the moment. |
| Task boundaries | Vague “be careful with AI.” | Name specific tasks AI can own (lit review, draft notes, study plans) and tasks that stay human (final dx, bad news, treatment escalation). |
| Teaching moment | Lecture the learner on AI hallucinations after the fact. | Walk through DEFT-AI live on a real case. Make it a 5-minute structured conversation. |
| Feedback style | “AI got that wrong.” | “Which assumption in the AI output could be wrong here? What in this patient argues for or against it?” |
| Prompting coaching | Ignore how they prompted. | Ask “what exactly did you type in?” Teach specificity, context, and chain-of-thought prompting. |
| Verification coaching | “Don’t trust AI” as a generic warning. | “Check one claim against UpToDate before using this output.” Make it a behavior, not a slogan. |
| Assessment design | Only evaluate performance with phones available. | Schedule regular unassisted assessments at the same difficulty. Morning report without devices. |
| Modeling | Pretend you don’t use AI yourself. | Narrate your own Zone 3 workflow out loud: “Here’s my thinking, here’s what I asked AI, here’s what I rejected.” |
6. The Trade-Off Worth Making
The deskilling concern around AI in medicine is real. But the framing most people use is off. We won’t stop AI from arriving in training. We get to decide which cognitive work we offload, what we reinvest the freed capacity in, and how we train residents and fellows to make those decisions well.
A fellow who offloads reference management and first-draft literature synthesis to AI and reinvests the freed hours in deep reading of the 3 key papers and bedside pattern recognition is not deskilled. They’re upskilled on the things that matter.
A fellow who offloads clinical reasoning to AI and scrolls social media with the freed time is deskilled on the thing that matters most.
Same tool. Different design. Different outcome.
Your job, whether you’re the learner or the supervisor, is to make the design decision deliberately, not let it happen by accident.
The next time AI shows up in your clinic, your lab meeting, or your writing session, don’t ask “should I use this?” Ask “what am I offloading, and what am I reinvesting the freed capacity into?”
Answer that honestly and you’re in Zone 3.
KEY REFERENCES:
- Abdulnour RE, Gin B, Boscardin CK. Educational Strategies for Clinical Supervision of Artificial Intelligence Use. N Engl J Med. 2025;393(8):786-97.
- Gerlich M. AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking. Societies. 2025;15:6.
- Jabbour S, et al. Measuring the Impact of AI in the Diagnosis of Hospitalized Patients. JAMA. 2023;330:2275-84.
- Karpicke JD, Blunt JR. Retrieval practice produces more learning than elaborative studying with concept mapping. Science. 2011;331:772-5.
- Kosmyna N, et al. EEG-based measurement of cognitive engagement during AI-assisted writing. arXiv:2506.08872. 2025 preprint.
- Wang H, Zhang L. Partnership orientation with AI and transformative learning outcomes. International Journal of Educational Technology in Higher Education. 2026.
- Dell’Acqua F, McFowland E, Mollick E, et al. Navigating the Jagged Technological Frontier. Harvard Business School Working Paper, 2023.
P.S. I’ll be running a webinar on How to use AI for research in the coming weeks. Please keep an eye out for the link next week.
Meanwhile, if you want to try a purpose built AI academic writing agent, you can try Research Boost FREE at https://researchboost.com/