

My lab has six members. Five of us have institutional IDs, payroll lines, and IRB credentials. The sixth does not. And you guessed it right (from the post title 🙂 – it’s Claude Code.
It does not attend lab meetings. It does not put its name on papers. But this quarter it has read more of our pipeline than any human on the team (of course all de-identified data). It brainstorms methods sections, screens abstracts, and maintains our running citation list. A meaningful portion of the lab’s institutional memory now lives in our Claude project.
This is not a metaphor. It is what an AI-augmented clinical research lab actually looks like in 2026. Roughly two-thirds of academic scientists have already started running their work this way [3,4]. Only 11.4 percent have had any institutional training on AI tools. Fewer than 10% of their institutions have a written policy on AI chatbot use [10]. The gap between adoption and governance is the structural problem of the next five years, and it will not resolve itself from the top down.
Naval Ravikant has argued that small, fully-connected teams of smart generalists outperform hierarchies once AI absorbs the coordination overhead. He was talking about hardware startups. He could have been describing my lab.
The lab is where the structural shift gets resolved. The rest of academia will follow, more slowly than most people realize and faster than most institutions are prepared for.
[A short note on methods. The 80-plus peer-reviewed citations in this post came together with Research Boost, the AI assistant for academic writing I built for my myself, my mentees and students but has since then grown to 500+ users (Thank you!). ]
1. AI is research infrastructure, not a productivity tool
The first framing to get right is that generative AI is now spanning multiple phases of the research process at once. A query-level analysis of more than 106,000 physician interactions with a generative AI platform found that medical research accounted for 60.2 percent of all queries [4]. A national survey of 2,534 Danish researchers identified three distinct user clusters across 32 use cases: AI as “work horse,” “language assistant,” and “research accelerator” [5]. When one technology spans idea generation, literature review, analysis, and writing simultaneously, it stops behaving like a specialized instrument and starts behaving like infrastructure. Like electricity. Like the internet.
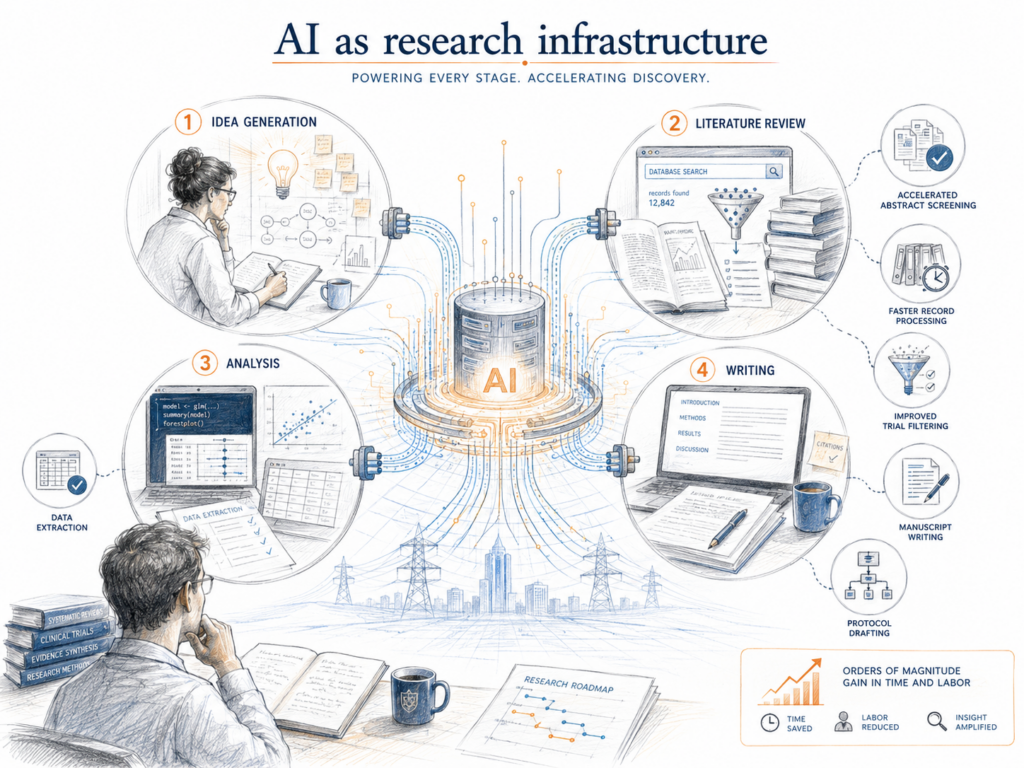
The capability evidence is now hard to dismiss.
→ LLM ensembles for abstract screening hit a sensitivity of 1.000 across 23 Cochrane reviews on a development set, exceeding the human maximum of 0.775 [6].
→ A three-layer GPT-4 strategy processed approximately 110 records/ min at a sensitivity of 0.962, compressing weeks of screening into hours [7].
→ GPT-4o-mini outperformed the Cochrane highly sensitive search strategy on specificity for randomized controlled trial filtering, at 100 percent sensitivity [8].
→ For binary outcome data extraction, LLM accuracy reached 71 to 94%, approaching or exceeding typical single-human extraction at 65 percent [9].
→ A blinded non-inferiority study found no significant quality difference between GPT-4 and human researchers in writing introduction sections, and 59% of assessors preferred the AI-generated versions [10].
→ Retrieval-augmented LLMs improved clinical trial protocol drafting with 25 to 50% time reductions and content relevance scores above 80 percent [11].
These are not marginal gains in convenience. They are order-of-magnitude shifts in time and labor on tasks that have historically been rate-limited by human reading speed.
2. What “Claude Code as a lab member” actually means
In my lab, the role map is concrete. I direct the work and sign off on framing and clinical claims. The postdoc runs analyses, drafts manuscripts, and iterates on prompts. The research coordinator handles eligibility prescreening, regulatory paperwork, and scheduling. The clinical partner validates study population definitions and reviews patient-facing language. The graduate student triages literature and runs sensitivity checks. Claude Code sits across all of these as a tireless reader, drafter, and coordinator.
This pattern matches what the survey evidence describes. Trainees adopt fastest. A multi-country survey found that 73% of medical students had used generative AI in research, compared with 59% of physicians [2]. Senior physicians generate proportionally more research-related queries than younger colleagues, while younger users pose more clinical questions [4]. The PI sets the norms. The trainee uses the tool most. The coordinator’s tasks are often the most automatable yet the least supported by formal training [3].
The boundary between what AI does well and what it does poorly is also clear, and it has to be respected.
Strong: structured screening, binary outcome extraction, draft generation, summarization, eligibility prescreening.
Weak: continuous outcome extraction (24 to 56% accuracy [9]), critical analysis in literature reviews [12], complex reasoning tasks (F1 scores below 0.52 in a Hospital Clínic Barcelona hackathon evaluation [13]).
Surface fluency can also mask substantive gaps in dangerous ways. ChatGPT abstracts were rated more readable than originals in 62% of blinded assessments, even though the originals scored higher on CONSORT-A reporting standards [14]. Blinded reviewers correctly identified only 68% of AI-generated abstracts and misclassified 14% of original abstracts as AI-generated [15]. Fellowship-trained orthopaedic surgery reviewers caught AI-generated abstracts at a rate of just 62% [16].
The discipline this forces is “generate then verify (always).” Every output goes through a checking loop. The verification loop is where domain expertise lives. A medical student can run the AI. Only the PI or the clinical partner can tell when the AI has confidently produced something wrong. That is a problem. And why disclosures are important within and outside of labs.
3. The hard constraint: PHI, governance, and what almost everyone is getting wrong
Clinical research labs do not get to pretend the data is generic. Every clinical note, every lab result, every patient identifier creates a privacy risk surface, and most labs are handling this badly.
A scoping review of 464 studies involving patient data and LLMs found that 38.4% failed to report whether effective privacy protection measures were implemented [17]. Among those that did report, 98.7 percent did not assess the degree of de-identification achieved. Nearly ten percent of those studies did not report ethics committee approval, and 32 percent did not report consent information [17]. Adoption is running ahead of compliance discipline.
De-identification is also less protective than people assume. A study of electronic health records from 731,850 patients showed that the average patient was uniquely identifiable from all others 98.4 percent of the time based on laboratory test orders alone [18]. Lab orders are not classified as direct identifiers. They identify patients anyway through combinatorial patterns. Even high-performing de-identification systems with recall above 95% leave substantial residual PHI when applied across millions of notes [19,20,21].
Institutional approved tools matter. A cross-sectional survey comparing two academic medical centers found that the center with institutional LLM access reported significantly lower liability concerns: 49.2% versus 66.7% reporting high concern [22]. Locally hosted models help but do not solve the problem. An evaluation of an offline Llama-2 model for radiology report anonymization showed perfect precision for some PHI categories and recall as low as 0.52 for dates [23].
3 things every lab should put in place this quarter:
→ A written list of which AI tools are approved for which data types. Not “ChatGPT is fine.” De-identified summary text in one tool. Coding assistance with no patient data in another. Anything PHI-touching only in institutionally sanctioned environments.
→ Documentation of prompts, model versions, and data inputs for every analytic use. Reproducibility now requires this [24,25,26]. IRB scrutiny will eventually require it.
→ Treat AI processing of patient-derived data as a protocol-relevant activity. Document it. Tell your IRB before deployment, not after.
4. Why the “Lindy effect” will not save academia this time
The Lindy effect says the longer a process has lasted, the longer it will keep lasting. Tenure, peer review, IRBs, NIH study sections, and journals all pass that test by decades or centuries. This is one of the few moments where Lindy fails.
Three forcing functions are already in motion.
The trainee market. Medical and graduate students entering programs in 2026 have used AI through every paper they wrote in college. They will choose mentors and institutions that let them keep working that way. The 73% versus 59% gap between students and faculty [2] is not a snapshot. It is a one-way arrow. Labs that signal “we don’t use AI here” will get the candidates who could not get into the others.
The verification crisis. Surface fluency is now decoupled from underlying quality. AI-generated abstracts pass blinded human review at rates that should worry any peer review system [15,16]. Targeted manipulation of as little as 1.1% of an LLM’s weights can inject incorrect biomedical facts into otherwise normal-looking outputs [27]. The signals reviewers and promotion committees rely on (polished prose, fluent argumentation, comprehensive citations) are now easier to produce without underlying judgment. A study of LLM screening for clinical guideline development showed sensitivity of 0.49 with a baseline prompt and 0.89 with a modified one [28]. The same model produces dramatically different outputs depending on how it is queried. Institutions that do not adapt their evaluation criteria will get the work product they incentivize.
The disclosure gap. A cross-sectional audit of 162 STM publishers found that 87.5% require specific disclosure of AI chatbot use [29]. A survey of global clinical researchers found that 40.5 percent of those who had used LLMs in publications did not acknowledge their use [30]. That gap closes one of two ways: clearer norms and audit trails inside labs, or external enforcement after a public scandal. The first option is cheaper.
A reassuring data point on the other side. A US survey found that 84% of academic scientists who currently use AI intend to continue [1]. Faculty anxiety is real but differentiated: concerns about specific risks predict adoption decisions, while general anxiety about the profession does not [31]. Researchers are not broadly resistant to AI. They want clearer boundaries.
The Lindy effect does not survive a structural shift in inputs. The printing press did not respect the Lindy effect of monastic scribes. The telegraph did not respect the Lindy effect of letter mail. AI will not respect the Lindy effect of the academic department.
5. The extreme: an institution organized as an intelligence
Block, the company Jack Dorsey (founder and former CEO of twitter) runs, has published its plan to build itself as an “intelligence” rather than a hierarchy. Four pieces: capabilities (the things only that company can do), a world model of its own operations and customer reality, an intelligence layer that composes capabilities for specific moments, and three human roles (individual contributors, directly responsible individuals, player-coaches). No permanent middle management.
Map that to a department of medicine.
The capabilities are the things only your institution offers: an active IRB, REDCap instances, biorepositories, EHR data extracts, defined clinic populations, disease registries, NIH-funded core facilities. The world model would be a continuously updated picture of every active project, grant deadline, IRB submission, manuscript stage, and trainee progression. The intelligence layer would compose them on demand. A K-awardee approaches the end of their funding. The system flags it, identifies which R01 mechanisms fit, brainstorms and suggests different directions based on the awardee’s last three papers and grants, and surfaces the three faculty most cited in their recent work as potential collaborators.
Could a department do this? Yes in theory. Almost certainly not in the next five years. Health data lives in fragmented systems wrapped in HIPAA, FERPA, and institutional politics. Epic was not built to share data with anything that wants to think about it. IRB submissions live in a portal that does not talk to the grants office. Grants live in a portal that does not talk to the manuscripts office. The manuscripts office does not exist.
What is realistic in the near term: research administration tools will absorb AI first. Grant tracking, manuscript pipelines, lab notebook search, and reproducibility audits are the obvious targets. Across 2,271 evidence syntheses published between 2017 and 2024, only about five percent explicitly reported using machine learning, with most uses limited to screening [32]. The structural shift is still early. Block may be the north star. The lab is the starting line.
6. What to do this quarter
5 concrete moves. The institution will move last. Start at the unit you control.
1. Make your lab’s work machine-readable. Protocols in plain text (.md files). Code in a repo. Decisions documented in shared notes. Prompt logs alongside analysis scripts. Reproducibility in AI-augmented research now requires versioned prompts, model identifiers, and output artifacts [24,25,26]. The minimum viable version is a shared document with three columns: prompt, model version, output location. Start there.
2. Train your trainees in delegation. A researcher who knows how to brief an AI on grant aims and verify the output will outproduce one who does not. The skills are management 101 applied to a new kind of teammate. A pre-post study of higher-education staff found a significant and large increase in generative AI use after even a brief structured course [33]. Brief works. Do not wait for the institution to organize it.
3. Pick one workflow per quarter and rebuild it with AI in the middle. Reference vetting. First-pass methods drafts. Internal peer review for papers, grants before submission. Eligibility prescreening. The Hospital Clínic Barcelona hackathon showed that structured tasks scaled well (entity recognition reached 90.5 percent accuracy, summarization exceeded 90 percent clinician concordance) while complex reasoning tasks did not [13]. Choose accordingly.
4. Build verification into the workflow, not as an afterthought. Prompt engineering studies show Fleiss kappa for LLM consistency ranging from −0.002 to 0.984 depending on the prompt [24]. The same model produces dramatically different outputs across prompts. Build checklists. Validate before scaling. Re-validate after model updates.
5. Address the equity gradient inside your lab. A large German survey found that female researchers showed a 7% decrease in AI tool usage and advanced-career researchers a 19% decrease compared with peers [34]. If your trainees adopt fastest and your senior people slowest, your lab’s institutional knowledge becomes the bottleneck. Senior people who refuse to learn from junior ones will fall behind. The reverse failure mode (junior people using AI without absorbing tacit clinical knowledge) is just as costly. Both have to be managed deliberately.
The departments that get to the structural shift first will not be the ones with the largest technology budget. They will be the ones whose labs already integrated their sixth member.
The literature review behind this post took just one focused session with Research Boost instead of a few weekends in PubMed. The same workflow is available in your lab right now. Preparation is the difference between being early or being left behind.
References
- Arroyo-Machado W, Ma J, Chen T, Johnson TP, Islam S, Michalegko L, et al. Generative AI and academic scientists in US universities: Perception, experience, and adoption intentions. PLOS One. 2025;20(8):e0330416. doi:10.1371/journal.pone.0330416
- Alhowaish TS, Alshafi NI, Aldekhyyel RN, Mesallam TA, Farahat M, Temsah M, et al. Generative artificial intelligence use in medical research: A medical student vs. physician survey from Saudi Arabia. International Journal of Medical Informatics. 2026;215:106458. doi:10.1016/j.ijmedinf.2026.106458
- Ng JY, Maduranayagam SG, Suthakar N, Li A, Lokker C, Iorio A, et al. Attitudes and perceptions of medical researchers towards the use of artificial intelligence chatbots in the scientific process: an international cross-sectional survey. The Lancet Digital Health. 2025;7(1):e94-e102. doi:10.1016/s2589-7500(24)00202-4
- Qiu L, Tang C, Bi X, Burtch G, Chen Y, Zhang H. Physician Use of Large Language Models: A Quantitative Study Based on Large-Scale Query-Level Data. Journal of Medical Internet Research. 2025;27:e76941. doi:10.2196/76941
- Andersen JP, Degn L, Fishberg R, Graversen EK, Horbach SP, Schmidt EK, et al. Generative Artificial Intelligence (GenAI) in the research process – A survey of researchers’ practices and perceptions. Technology in Society. 2025;81:102813. doi:10.1016/j.techsoc.2025.102813
- Sanghera R, Thirunavukarasu AJ, Khoury ME, O’Logbon J, Chen Y, Watt A, et al. High-performance automated abstract screening with large language model ensembles. Journal of the American Medical Informatics Association. 2025;32(5):893-904. doi:10.1093/jamia/ocaf050
- Matsui K, Utsumi T, Aoki Y, Maruki T, Takeshima M, Takaesu Y. Human-Comparable Sensitivity of Large Language Models in Identifying Eligible Studies Through Title and Abstract Screening: 3-Layer Strategy Using GPT-3.5 and GPT-4 for Systematic Reviews. Journal of Medical Internet Research. 2024;26:e52758. doi:10.2196/52758
- Tran V, Possamai CG, Boutron I, Ravaud P. Using large language models to directly screen electronic databases as an alternative to traditional search strategies such as the Cochrane highly sensitive search for filtering randomized controlled trials in systematic reviews. Research Synthesis Methods. 2025;16(6):1035-1041. doi:10.1017/rsm.2025.10034
- Yisha Z, Zou P, Li S, Zhang L, Guo L, Gu A, et al. Assessing data extraction in randomized clinical trials with large language models. BMC Medical Research Methodology. 2026;26(1). doi:10.1186/s12874-025-02729-5
- Sikander B, Baker JJ, Deveci CD, Lund L, Rosenberg J. ChatGPT-4 and Human Researchers Are Equal in Writing Scientific Introduction Sections: A Blinded, Randomized, Non-inferiority Controlled Study. Cureus. 2023. doi:10.7759/cureus.49019
- Markey N, El-Mansouri I, Rensonnet G, Langen CV, Meier C. From RAGs to riches: Utilizing large language models to write documents for clinical trials. Clinical Trials. 2025;22(5):626-631. doi:10.1177/17407745251320806
- Muddana C, Wang B, Sun P, Tang YJ. Comparative evaluation of large language models for biotechnology review writing. Biotechnology Advances. 2026;88:108814. doi:10.1016/j.biotechadv.2026.108814
- Frid S, Bassegoda O, Mahamud MAC, Sanjuan G, Hoz MÁADL, Celi L, et al. Bridging generative AI and healthcare practice: insights from the GenAI Health Hackathon at Hospital Clínic de Barcelona. BMJ Health & Care Informatics. 2025;32(1):e101640. doi:10.1136/bmjhci-2025-101640
- Hwang T, Aggarwal N, Khan PZ, Roberts T, Mahmood A, Griffiths MM, et al. Can ChatGPT assist authors with abstract writing in medical journals? Evaluating the quality of scientific abstracts generated by ChatGPT and original abstracts. PLOS ONE. 2024;19(2):e0297701. doi:10.1371/journal.pone.0297701
- Gao CA, Howard FM, Markov NS, Dyer EC, Ramesh S, Luo Y, et al. Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers. npj Digital Medicine. 2023;6(1). doi:10.1038/s41746-023-00819-6
- Stadler RD, Sudah SY, Moverman MA, Denard PJ, Duralde XA, Garrigues GE, et al. Identification of ChatGPT‐Generated Abstracts Within Shoulder and Elbow Surgery Poses a Challenge for Reviewers. Arthroscopy. 2024;41(4):916. doi:10.1016/j.arthro.2024.06.045
- Zhong X, Li S, Chen Z, Ge L, Yu D, Wang S, et al. Considerations for Patient Privacy of Large Language Models in Health Care: Scoping Review (Preprint). doi:10.2196/preprints.76571
- Johnson KW, Freitas JKD, Glicksberg BS, Bobe JR, Dudley JT. Evaluation of patient re-identification using laboratory test orders and mitigation via latent space variables. Biocomputing 2019. 2018:415-426. doi:10.1142/9789813279827_0038
- Deleger L, Molnar K, Savova G, Xia F, Lingren T, Li Q, et al. Large-scale evaluation of automated clinical note de-identification and its impact on information extraction. Journal of the American Medical Informatics Association. 2013;20(1):84-94. doi:10.1136/amiajnl-2012-001012
- Norgeot B, Muenzen K, Peterson TA, Fan X, Glicksberg BS, Schenk G, et al. Protected Health Information filter (Philter): accurately and securely de-identifying free-text clinical notes. npj Digital Medicine. 2020;3(1). doi:10.1038/s41746-020-0258-y
- Murugadoss K, Rajasekharan A, Malin B, Agarwal V, Bade S, Anderson JR, et al. Building a best-in-class automated de-identification tool for electronic health records through ensemble learning. Patterns. 2021;2(6):100255. doi:10.1016/j.patter.2021.100255
- Hong HJ, Shah NH, Pfeffer MA, Lehmann LS. Physician Perspectives on Large Language Models in Health Care: A Cross-Sectional Survey Study. Applied Clinical Informatics. 2025;16(05):1738-1748. doi:10.1055/a-2735-0527
- Langenbach MC, Foldyna B, Hadzic I, Langenbach IL, Raghu VK, Lu MT, et al. Automated anonymization of radiology reports: comparison of publicly available natural language processing and large language models. European Radiology. 2024;35(5):2634-2641. doi:10.1007/s00330-024-11148-x
- Wang L, Chen X, Deng X, Wen H, You M, Liu W, et al. Prompt engineering in consistency and reliability with the evidence-based guideline for LLMs. npj Digital Medicine. 2024;7(1). doi:10.1038/s41746-024-01029-4
- Beaulieu-Jones BK, Greene CS. Reproducibility of computational workflows is automated using continuous analysis. Nature Biotechnology. 2017;35(4):342-346. doi:10.1038/nbt.3780
- Bedő J, Di Stefano L, Papenfuss AT. Unifying package managers, workflow engines, and containers: Computational reproducibility with BioNix. GigaScience. 2020;9(11). doi:10.1093/gigascience/giaa121
- Han T, Nebelung S, Khader F, Wang T, Müller-Franzes G, Kuhl C, et al. Medical large language models are susceptible to targeted misinformation attacks. npj Digital Medicine. 2024;7(1). doi:10.1038/s41746-024-01282-7
- Oami T, Okada Y, Nakada T. Performance of a Large Language Model in Screening Citations. JAMA Network Open. 2024;7(7):e2420496. doi:10.1001/jamanetworkopen.2024.20496
- Bhavsar D, Duffy L, Jo H, Lokker C, Haynes RB, Iorio A, et al. Policies on artificial intelligence chatbots among academic publishers: a cross-sectional audit. Research Integrity and Peer Review. 2025;10(1). doi:10.1186/s41073-025-00158-y
- Mishra T, Sutanto E, Rossanti R, Pant N, Ashraf A, Raut A, et al. Use of large language models as artificial intelligence tools in academic research and publishing among global clinical researchers. Scientific Reports. 2024;14(1). doi:10.1038/s41598-024-81370-6
- Verano-Tacoronte D, Bolívar-Cruz A, Sosa-Cabrera S. Are university teachers ready for generative artificial intelligence? Unpacking faculty anxiety in the ChatGPT era. Education and Information Technologies. 2025;30(14):20495-20522. doi:10.1007/s10639-025-13585-7
- Review for “Artificial Intelligence and Automation in Evidence Synthesis: An Investigation of Methods Employed in Cochrane, Campbell Collaboration, and Environmental Evidence Reviews”. doi:10.1002/cesm.70046/v1/review2
- Møgelvang A, Cipriani E, Grassini S. Generative AI in Action: Acceptance and Use Among Higher Education Staff Pre- and Post-training. Technology, Knowledge and Learning. 2025. doi:10.1007/s10758-025-09915-w
- Chugunova M, Harhoff D, Hölzle K, Kaschub V, Malagimani S, Morgalla U, et al. Who uses AI in research, and for what? Large-scale survey evidence from Germany. Research Policy. 2026;55(2):105381. doi:10.1016/j.respol.2025.105381
Top Papers on AI in research this week:
- AI Outperforms ER Physicians in Diagnosis – Harvard researchers published a study in Science this week showing OpenAI’s o1 model correctly identified the exact or close diagnosis in 67% of emergency triage cases. Two attending physicians scored 55% and 50% on the same cases. The AI also outperformed a group of physicians on complex case reports from NEJM, though researchers cautioned it tended to order unnecessary tests. (I’d caution against overinterpreting these findings to AI physicians taking over- real-world is too messy and consequences of error too high.)
- LLMs Stumble on Basic Hospital Admin Work – Mount Sinai scientists, publishing in PLOS Digital Health this week, tested nine leading LLMs on two routine tasks: counting patients who meet a clinical condition and filtering records by multiple criteria. The dataset contained 50,000 real emergency department visits. Accuracy deteriorated as the data grew larger. Only models that generated and executed code approached perfect performance.
- AI Inflates Journal Submissions but Undercuts Quality – Organization Science analyzed nearly 7,000 manuscript submissions and more than 10,000 peer reviews spanning 2021 to 2026. Submissions rose 42% since advanced LLMs became widely available. Writing quality fell 1.28 standard deviations from its 2021 baseline, and AI-assisted papers faced higher rejection rates despite their polished surfaces. No wonder how I have been getting so many review requests this year (don’t think it has to do anything with my resume).
Top Papers on AI in education this week:
- Social Learning Beats Solo AI Tutoring – An arXiv study tested whether multi-agent LLM setups outperform single-tutor models for learning. Students who worked with both a tutor agent and peer agents scored highest on unassisted post-session tests. Peer interaction added a measurable gain beyond what tutoring alone produced.
- AI Tools Improve Outcomes Through Engagement – A paper in Computers in Human Behavior Reports examined AI learning tools through a cognitive load lens. Both tool usage frequency and perceived usefulness predicted better learning outcomes. Student engagement partially mediated those effects, suggesting active participation with the tool matters as much as the tool’s features.
- AI in Schools: What’s Actually Working – This month’s field roundup from Filament Games captures three notable signals. Gemini is now an official AI provider for Moodle, bringing summarization directly into the learning management system. More than 400 universities have joined Google’s AI for Education Accelerator in under a year. At one Illinois middle school, eighth graders who spent a full year testing Gemini concluded that AI cannot replace the human connection of a supportive teacher (I’m sure we all agree).
📌 And a reminder, I’ll be giving Academic Writing with AI: Live Masterclass tomorrow (May 9, 2026, 10am CDT)- you can still register here FREE: https://risingresearcheracademy.easywebinar.live/event-registration-9