

1960: If you can’t explain it simply, you don’t understand it. 2026: If you can’t teach AI to do it, you don’t own it.
A few years ago, a colleague pitched me on building a virtual rheumatology clinic. I shut it down on the spot.
Evaluating complex psoriatic arthritis and spondyloarthritis patients over video seemed close to impossible. I had tried during COVID. Most visits ended the same way: a steroid script and a follow-up in person. The central problem in these patients is figuring out whether their pain comes from inflammatory disease flaring or coexisting fibromyalgia. Most of my patients have both. Between 18% and 64% of PsA patients have coexisting fibromyalgia, and when that overlap is missed, disease activity scores reflect fibromyalgia symptoms rather than true inflammation, driving overtreatment. Imaging helps sometimes. Labs can be normal. The diagnostic call lives somewhere else.
He pushed back. “What are you actually doing when you separate them?”
I could not answer.
I called it intuition. A decade of clinic. Thousands of patients. A feel for it. None of that was a teaching plan.
That conversation forced me to sit down and ask the uncomfortable question I had been avoiding: what am I actually looking at?
Once I stopped hiding behind the word intuition, my list got specific:
- Asymmetric tenderness on exam. Psoriatic arthritis joint involvement is often asymmetric, while rheumatoid arthritis is predominantly symmetric, and fibromyalgia tenderness is widespread rather than joint-specific.
- Interphalangeal joint involvement at the thumb (specific for psoriatic arthritis).
- Enthesitis at predictable tender points versus diffuse soft-tissue pain. The cleanest data on this come from Marchesoni and colleagues, who found that ≥6 fibromyalgia-associated somatic symptoms and ≥8 tender points were the best predictors of fibromyalgia in patients with PsA.
- How the patient describes morning stiffness, not just how long it lasted.
- Non-verbal cues during history and exam.
Five concrete signals. Not magic. Not taste. Pattern recognition I had never bothered to articulate.
Of course all of this still requires a good clinical exam, which is still a very human endeavor (robotics hasn’t had its ChatGPT moment yet). But the point is that this can be taught. Great educators are the ones are able to crystallize their intuition and judgement into something they can put on paper (instead of just telling you…”it depends…”).
1. Most “judgment” is pattern recognition you have not written down

When you say a paper has weak methods, you are not having a mystical experience. You are recognizing a pattern. A control group that does not match the exposure population. A not so well defined primary outcome buried in supplementary tables. A statistical test that does not fit the data structure.
When you say a Discussion section feels self-congratulatory, you are pattern matching too. Overreach in the opening paragraph. Limitations smuggled in at the end. Mechanism claims without mechanism data.
This is exactly what the decision science literature shows. In their joint paper on intuitive expertise, Kahneman and Klein build on Simon’s definition of intuition as the recognition of patterns stored in memory. Klein’s recognition-primed decision model frames expert judgment as pattern matching combined with mental simulation. You have run those algorithms thousands of times. They feel like intuition because you stopped consciously processing them. That is what expertise looks like from the inside. It is also why you cannot teach it without slowing down.
Michael Polanyi gave this its most famous name, the tacit dimension: “we know more than we can tell.” In medical education, the transmission of this kind of knowledge, often hard to articulate, is what enables learners to perform tasks effectively and safely. The same problem shows up in research training. The mentor knows. The mentee cannot extract it. And until recently, neither side had a strong incentive to force the issue.
AI changed that incentive.
2. The Move 37 moment
I built Research Boost because my mentees kept hitting the same walls I had hit. They needed help writing a Discussion section. They needed help structuring a Methods paragraph. They needed help thinking through a Results narrative.
For months, I told myself you could not capture academic writing nuance in a text file. The voice, the flow, the way you weave evidence into argument. Too tacit. Too earned.
I was wrong.
When I sat down to teach a model what I actually do, I had to slow my own process down. How do I open paragraph one of a Discussion section? What anchors paragraph two? When do I bring in mechanism versus when do I bring in arguments on other studies? Each move got written down. So did the failure modes, so the model would know what to avoid.
Two pages of instructions turned into twenty.
Then Research Boost wrote a Discussion section better than my first draft.
That was my Move 37. The reference is to AlphaGo’s (Deep mind’s neural network trained to play Go) second game against Lee Sedol in March 2016, when AlphaGo placed a stone on the fifth line in a position so unusual (and alien) that professional commentators initially assumed it was a mistake. But later proved to be “the” winning move. The broader lesson was that AI systems can explore strategy spaces in ways that transcend their training data. Most of what I called judgment, taste, and intuition was an algorithm running in my head. The only cost to extracting it was the discomfort of admitting it could be extracted at all. And then sitting down (for days) to put it into words.
3. The bottleneck has moved
For a decade, the limit on academic output was your writing speed. How fast you could draft. How fast you could edit. How fast you could turn around revisions.
That limit is gone. AI drafts faster than any of us.
The new limit is how clearly you can describe what good looks like. The researcher who can articulate their standards in writing beats the researcher who can only feel them. You need to be able to write down:
- What makes a Methods paragraph honest versus evasive.
- What separates a clean Results narrative from a noisy one.
- What turns a Discussion section into a sales pitch.
- What red flags show up in the first 5 sentences of a weak abstract.
- What makes a Limitations paragraph credible versus performative.
If you can write these down, you can train an AI on them and run a hundred drafting cycles in a week. If you cannot, you are stuck hand-crafting every draft.
This is the same lesson business operators learned a decade earlier. New hires fail when you cannot define what good looks like. AI agents fail for the same reason. The fix is not better prompts. The fix is observable standards, written out, with examples of pass and fail.
4. Three steps to extract your judgment into a file
This is what has worked for me:
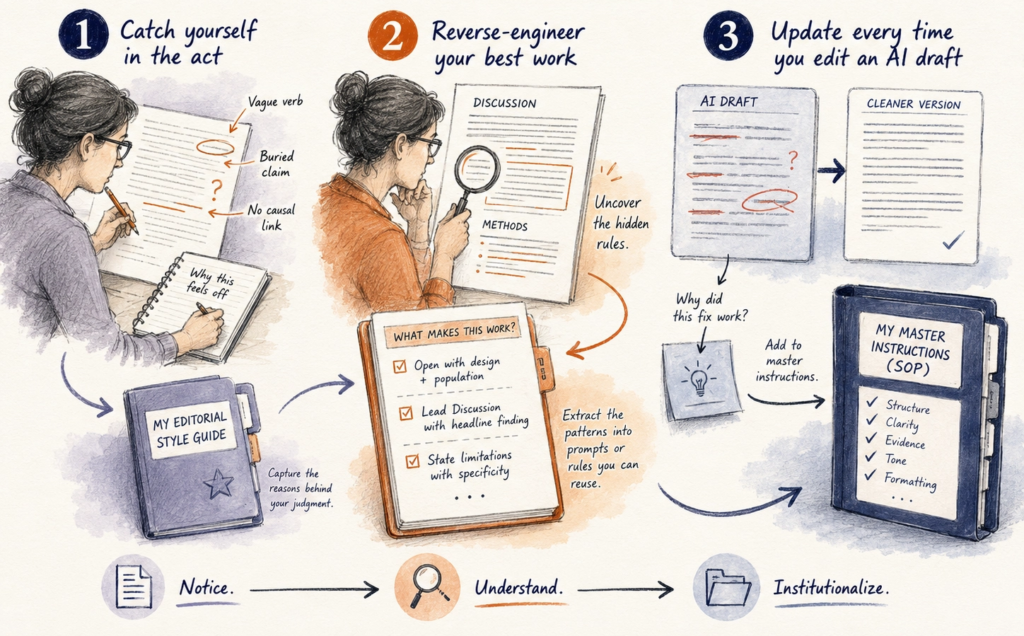
➡ Catch yourself in the act. The next time you read a paragraph and think “this is off,” stop. Do not fix it yet. Write down three specific reasons it is off. Vague verb. Buried claim. No causal link to the prior sentence. After a month of doing this, that file is your editorial style guide.
➡ Reverse-engineer your best work. Pull the cleanest Discussion or Methods section you have ever written. Read it slowly. Ask: what rules did I follow without naming? Maybe you always open Methods with the design and population. Maybe your first Discussion paragraph is one sentence summarizing the headline finding. Each unwritten rule becomes a line in your prompt file.
➡ Update every time you edit an AI draft. When you fix an AI output, do not just fix it. Ask why the fix worked. Add that reason to your master instructions. After 6 weeks you will have a personal SOP nobody else can replicate, because it is built from your specific judgment on your specific kind of research.
(I gave an example above on manuscript writing but it could be for any task in your personal or professional life.)
5. The new test of expertise
Twenty years ago, the test was your H-index. Ten years ago, it was your funding portfolio.
In 2026, the test is whether you can put your research judgment into a text file clear enough that a machine can execute on it.
Your edge is not the model you use. (Your competitors are using the same models.)
Your edge is the text file behind it.
The uncomfortable part of this shift is what it forces you to admit. The parts of your expertise you treated as ineffable were mostly unexamined. The day you write them down is the day you actually own them.
NOTE: Teaching AI is often harder than teaching humans how to do it. The instructions need to be very discreet, clear, with no room for ambiguity. Which is precise why → if you go on this journey, you will understand and sharpen your skill much better than any other learning technique.
Your move
What is one piece of research judgment you have never tried to write down?
Pick the smallest one. Three lines is enough to start. Most of you will find, like I did, that what you thought was a mysterious deep well is 20 pages of instructions you had been carrying around in your head.
Top Papers on AI in Research This Week
- LLMs Supercharge Scientific Output but Erode Quality Signals – A Science study of 2.1 million preprints found that researchers adopting LLMs publish between 24% and 89% more papers. The productivity bump was sharpest for non-native English speakers at Asian institutions. The catch: writing sophistication no longer reliably predicts research quality. Polished prose is now cheap to produce. Identifying genuinely important work is getting harder.
- MedResearchBench Sets a New Clinical AI Standard – A new benchmark designed specifically to evaluate AI agents on clinical medical research tasks was released publicly. It covers 16 tasks across 7 domains, including cardiovascular, oncology, mental health, and infectious disease. Each task is drawn from NHANES and SEER data, with ground truth from 16 published papers. AI performance is judged on statistical methodology, clinical interpretation, and reporting compliance.
- AAAI 2026 Reviews 20,000 Papers With AI in Under 24 Hours – For the first time, AAAI deployed an AI-assisted review system across its full main-track submission pool. The entire batch was processed in less than a day at under $1 per paper. AI-generated reviews scored better than human reviews in 6 of 9 evaluation categories. No human reviewer was replaced. The system focused on specific review elements, from content and readability to methodology and setup.
- LLMs Are Changing How Peer Reviews Sound – A Scientometrics study traced how AI adoption shifted the texture of peer reviews at top AI conferences. Reviews got longer and more fluent. What dropped was depth. Attention to originality, replicability, and nuanced critique all declined, even as surface-level clarity rose. The findings add to a growing body of evidence that LLMs optimize for form over substance.
- Isomorphic Labs Secures $2.1B to Scale AI Drug Design – DeepMind spinout Isomorphic Labs closed a $2.1B Series B on May 12, led by Thrive Capital. New backers include the UK Sovereign AI Fund, MGX, and Temasek. The company plans to advance its first AI-designed therapeutic into Phase I trials before the end of 2026. Existing partners Novartis, Lilly, and Johnson & Johnson remain on board. It is one of the largest private rounds ever raised for AI drug discovery.
Top Papers on AI in Education This Week
- AI Grading Cuts Cost Per Student From $10 to $0.15 – A Scientific Reports study tested 6 state-of-the-art LLMs for grading university-level assignments. DeepSeek-R1 aligned most closely with human evaluators on both score accuracy and feedback quality. Automated assessment cost just $0.15 per student, compared to roughly $10 for a 10-minute human review. Teachers still valued the narrative feedback, even when they questioned the automated scores.
- Grade-Specific AI Teachers Beat Prompt-Based Methods by 35 Points – Published in npj Artificial Intelligence, this paper introduces a framework for fine-tuning LLMs to produce age-appropriate content across six grade levels. The approach integrates seven readability metrics and was validated with 208 human participants. Grade-level alignment improved by 35.64 percentage points over standard prompting, without sacrificing factual accuracy. The work directly addresses global teacher shortages.
- Two AI Tutors Outperform One for Creative and Analytical Work – A controlled study with 562 participants paired Claude and ChatGPT together as AI tutors. Both LLM conditions improved essay quality. But single-model assistance produced idea-level homogeneity that the two-agent condition avoided. For SAT-level math, adding LLM peers alongside a tutor also changed error dynamics in ways a single tutor could not replicate. The results challenge the assumption that one capable model is always enough.
- NeurIPS 2026 Runs a Live AI Peer Review Experiment – NeurIPS is conducting a randomized study on how LLM assistance affects review quality and reviewer behavior in real time. Reviewers are assigned to one of three conditions: unassisted review, open-ended LLM access, or structured LLM guidance. Participating papers require author opt-in. The results will shape how scientific conferences integrate AI tools at scale going forward.
📌 P.S. Join my next live masterclass FREE: Academic Writing with AI (pick a time that works for you)
Register here for tomorrow, May 16, 07:00 am CDT Academic Writing with AI Live Masterclass: https://risingresearcheracademy.easywebinar.live/event-registration-10
Register here for May 30, 07:00 am CDT Academic Writing with AI Live Masterclass: https://risingresearcheracademy.easywebinar.live/event-registration-11